正则表达式是一组由字母和符号组成的特殊文本, 它可以用来从文本中找出满足你想要的格式的句子。
元字符
正则表达式主要依赖于元字符. 元字符不代表他们本身的字面意思, 他们都有特殊的含义. 一些元字符写在方括号中的时候有一些特殊的意思. 以下是一些元字符的介绍:
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符. |
| [ ] | 字符种类. 匹配方括号内的任意字符. |
| [^ ] | 否定的字符种类. 匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符. |
| + | 匹配>=1个重复的+号前的字符. |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符 (n <= num <= m). |
| (xyz) | 字符集, 匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 `[ ] ( ) { } . * + ? ^ $ \ |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
简写字符集
正则表达式提供一些常用的字符集简写. 如下:
| 简写 | 描述 |
|---|---|
| . | 除换行符外的所有字符 |
| \w | 匹配所有字母数字, 等同于 [a-zA-Z0-9_] |
| \W | 匹配所有非字母数字, 即符号, 等同于: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配所有空格字符, 等同于: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字符: [^\s] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \p | 匹配 CR/LF (等同于 \r\n),用来匹配 DOS 行终止符 |
零宽度断言(前后预查)
先行断言和后发断言都属于非捕获簇(不捕获文本 ,也不针对组合计进行计数). 先行断言用于判断所匹配的格式是否在另一个确定的格式之前, 匹配结果不包含该确定格式(仅作为约束).
例如, 我们想要获得所有跟在 $ 符号后的数字, 我们可以使用正后发断言 (?<=\$)[0-9\.]*. 这个表达式匹配 $ 开头, 之后跟着 0,1,2,3,4,5,6,7,8,9,. 这些字符可以出现大于等于 0 次.
零宽度断言如下:
| 符号 | 描述 |
|---|---|
| ?= | 正先行断言-存在 |
| ?! | 负先行断言-排除 |
| ?<= | 正后发断言-存在 |
| ?<! | 负后发断言-排除 |
?=... 正先行断言
?=... 正先行断言, 表示第一部分表达式之后必须跟着 ?=...定义的表达式.
返回结果只包含满足匹配条件的第一部分表达式. 定义一个正先行断言要使用 (). 在括号内部使用一个问号和等号: (?=...).
正先行断言的内容写在括号中的等号后面. 例如, 表达式 (T|t)he(?=\sfat) 匹配 The 和 the, 在括号中我们又定义了正先行断言 (?=\sfat) ,即 The 和 the 后面紧跟着 (空格)fat.
1 | "(T|t)he(?=\sfat)" => The fat cat sat on the mat. |
?!... 负先行断言
负先行断言 ?! 用于筛选所有匹配结果, 筛选条件为 其后不跟随着断言中定义的格式. 正先行断言 定义和 负先行断言 一样, 区别就是 = 替换成 ! 也就是 (?!...).
表达式 (T|t)he(?!\sfat) 匹配 The 和 the, 且其后不跟着 (空格)fat.
1 | "(T|t)he(?!\sfat)" => The fat cat sat on the mat. |
?<= ... 正后发断言
正后发断言 记作(?<=...) 用于筛选所有匹配结果, 筛选条件为 其前跟随着断言中定义的格式. 例如, 表达式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat, 且其前跟着 The 或 the.
1 | "(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat. |
?<!... 负后发断言
负后发断言 记作 (?<!...) 用于筛选所有匹配结果, 筛选条件为 其前不跟随着断言中定义的格式. 例如, 表达式 (?<!(T|t)he\s)(cat) 匹配 cat, 且其前不跟着 The 或 the.
1 | "(?<!(T|t)he\s)(cat)" => The cat sat on cat. |
标志
标志也叫模式修正符, 因为它可以用来修改表达式的搜索结果. 这些标志可以任意的组合使用, 它也是整个正则表达式的一部分.
| 标志 | 描述 |
|---|---|
| i | 忽略大小写. |
| g | 全局搜索. |
| m | 多行的: 锚点元字符 ^ $ 工作范围在每行的起始. |
贪婪匹配与惰性匹配 (Greedy vs lazy matching)
正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串。我们可以使用 ? 将贪婪匹配模式转化为惰性匹配模式。
1 | "/(.*at)/" => The fat cat sat on the mat. |
1 | "/(.*?at)/" => The fat cat sat on the mat. |
来源
点击learn-regex即可去查看更详细信息。
Regulex是一个JavaScript 正则表达式解析和可视化网站。具体效果参看👇示例。
示例
邮箱
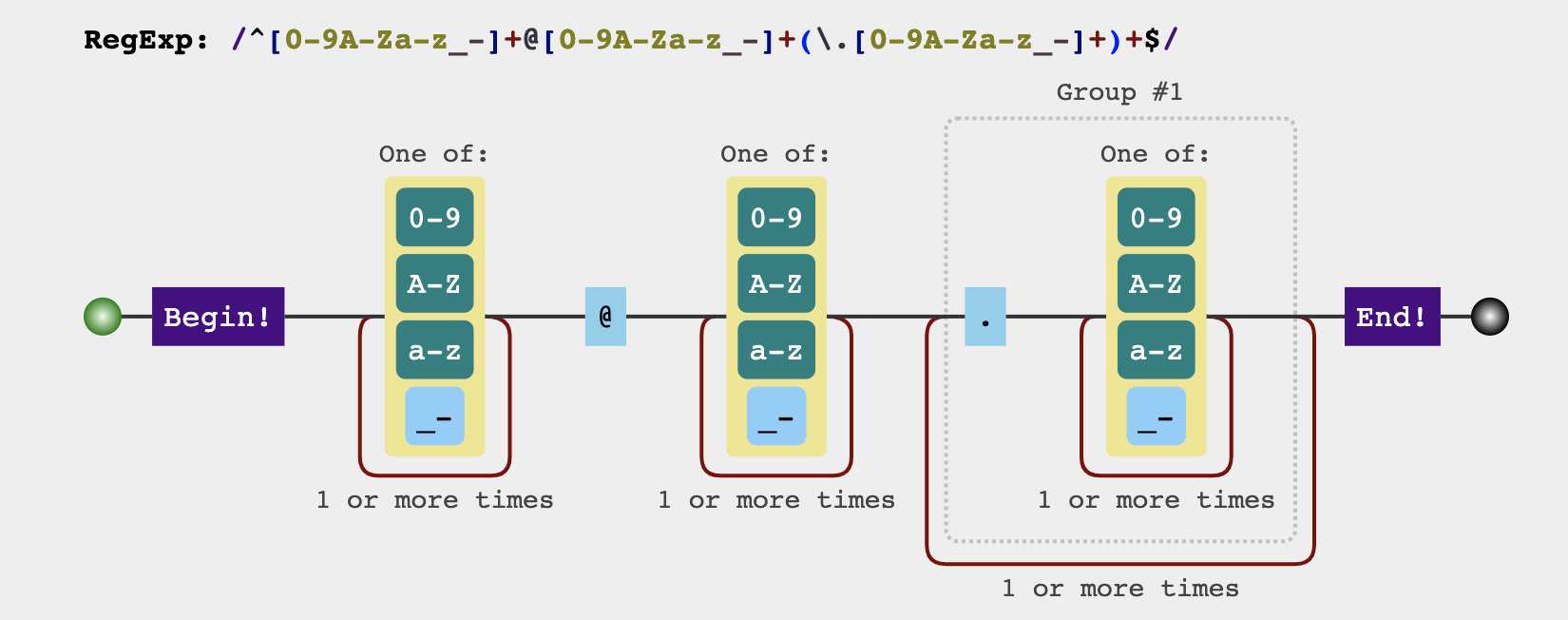
只允许英文字母、数字、下划线、英文句号、以及中划线组成。
1 | ^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$ |
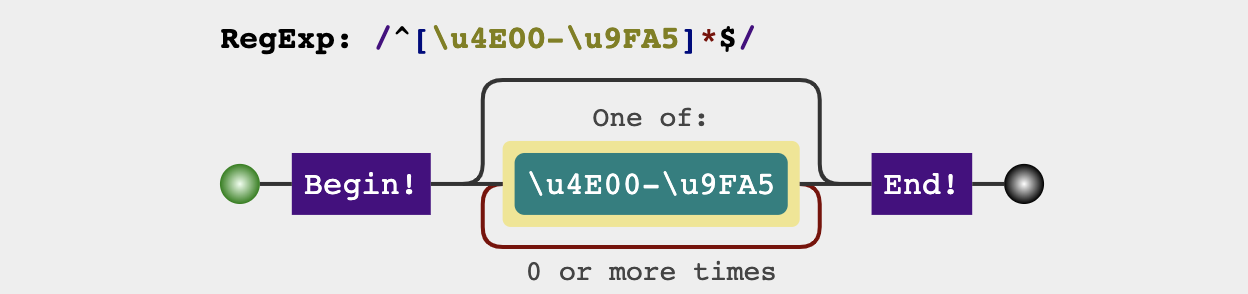
汉字
1 | ^[\u4e00-\u9fa5]{0,}$ |
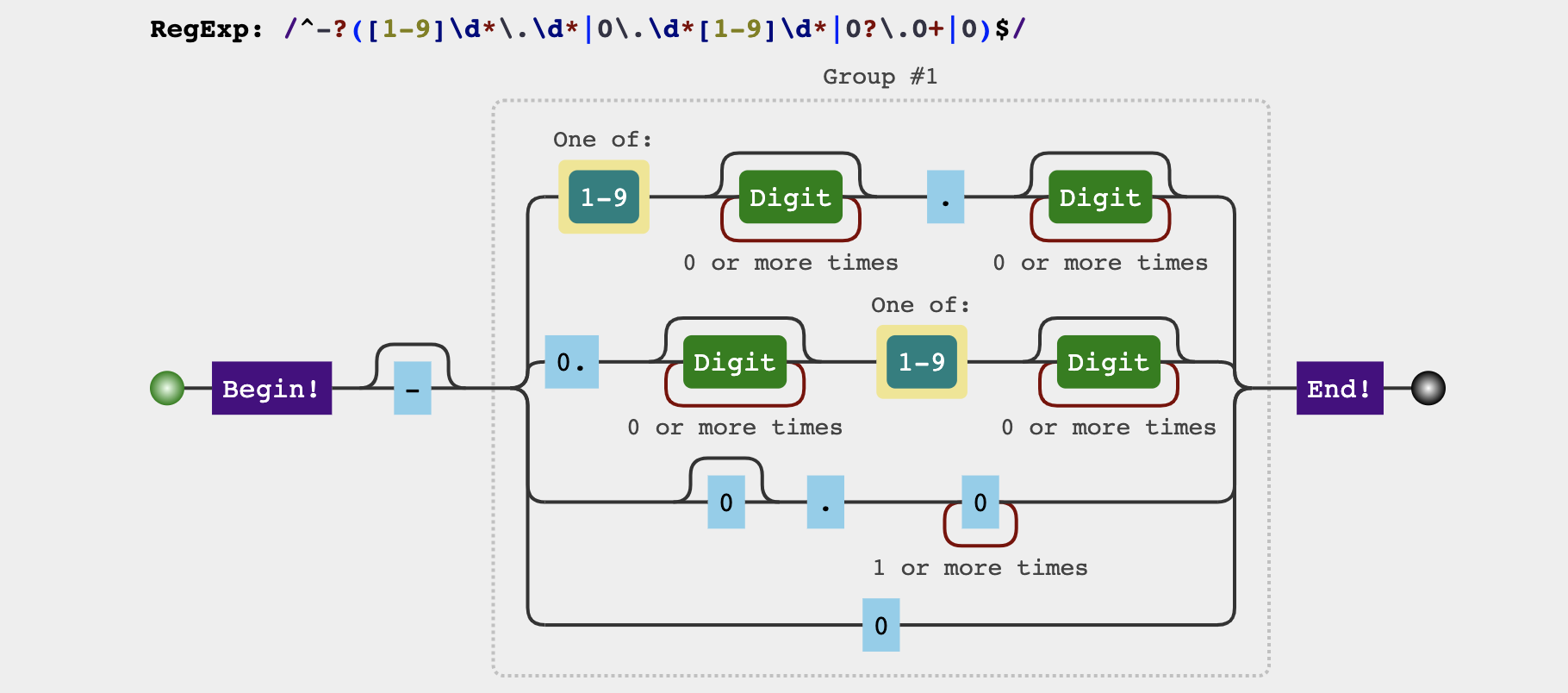
浮点数
1 | ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ |