前言
Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据。Java 中最常用的 Map 有两种,首先是 HashMap ,其次是 ConcurrentHashMap 。
HashMap
从整个 HashMap 的声明可以看出它内部是基于数组 + 链表实现的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。
基于 1.7
HashMap 在 jdk1.7 中的数据结构图: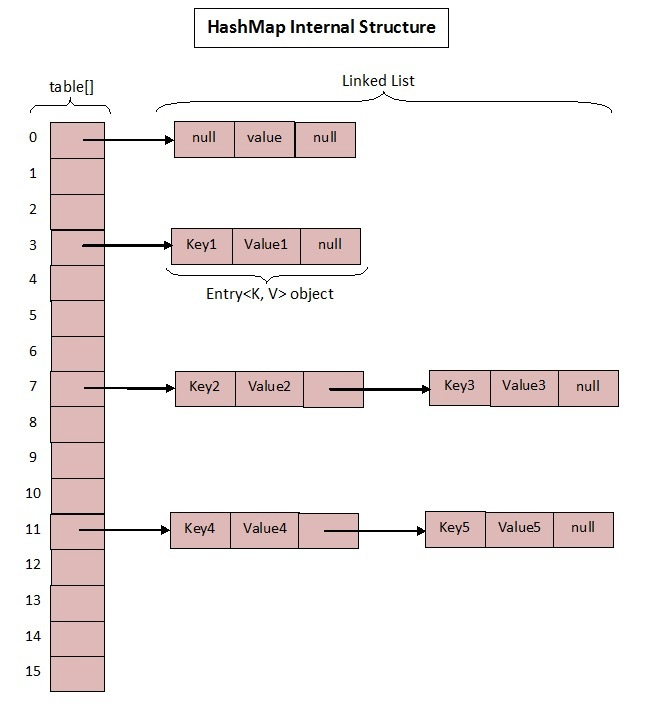
首先来看 jdk1.7 中的实现:
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //初始化桶大小,因为底层是数组,所以这是数组默认的大小。默认大小16 |
Map 在使用过程中不断的往里面存放数据,当数量达到了 threshold 就需要将当前容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
根据代码可以看到其实真正存放数据的是
1 | transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; |
这个数组,那么它又是如何定义的呢?
1 | // Entry 是 HashMap 中的一个内部类 |
以上即为 HashMap 的基本结构,接下来来看写入和获取方法:
put 方法
1 | public V put(K key, V value) { |
get 方法
1 | public V get(Object key) { |
链表死循环
基于 1.8
HashMap 在 jdk1.7 的实现中有个明显缺点:
当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为
O(N)。
因此 1.8 中对大链表做了优化,修改为红黑树之后查询效率直接提高到了 O(logn)。
话不多说,上🐎:
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
和 1.7 大体上都差不多,还是有几个重要的区别:
TREEIFY_THRESHOLD用于判断是否需要将链表转换为红黑树的阈值。Entry修改为Node。
Node 的核心组成其实也是和 1.7 中的 Entry 一样,存放的都是 key value hashcode next 等数据。
put 方法
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
get 方法
1 | public V get(Object key) { |
线程不安全
HashMap 在并发时可能出现的问题主要有三个方面:
如果多个线程同时使用 put 方法添加元素,而且假设正好存在两个 put 的 key 发生了碰撞(根据 hash 值计算的 bucket 一样),那么根据 HashMap 的实现,这两个 key 会添加到数组的同一个位置,这样最终就会发生其中一个线程 put 的数据被覆盖。
如果多个线程同时检测到元素个数超过 threshold,这样就会发生多个线程同时对 Node 数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给 table,也就是说其他线程的都会丢失,并且各自线程 put 的数据也丢失。
遍历方式
还有一个值得注意的是 HashMap 的遍历方式,通常有以下几种:
1 | Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator(); |
强烈建议使用第一种 EntrySet 进行遍历。第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低。
无论是 1.7 还是 1.8 其实都能看出 JDK 没有对它做任何的同步操作,所以并发会出问题,甚至 1.7 中出现死循环导致系统不可用(1.8 已经修复死循环问题)。
因此 JDK 推出了专项专用的 ConcurrentHashMap ,该类位于 java.util.concurrent 包下,专门用于解决并发问题。