ASCII - Unicode - UTF-8
ASCII
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
汉字使用的符号多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
Unicode
Unicode应运而生,Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
Unicode 是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
不过,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。这就导致 Unicode 有多种存储方式,即有许多种不同的二进制格式,可以用来表示 Unicode。如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。浏览网页的时候,服务器会把动态生成的 Unicode 内容转换为 UTF-8 再传输到浏览器。很多网页的源码上会有类似 <meta charset="UTF-8" />的信息,表示该网页正是用的 UTF-8 编码。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
1 | Unicode符号范围 | UTF-8编码方式 |
例如: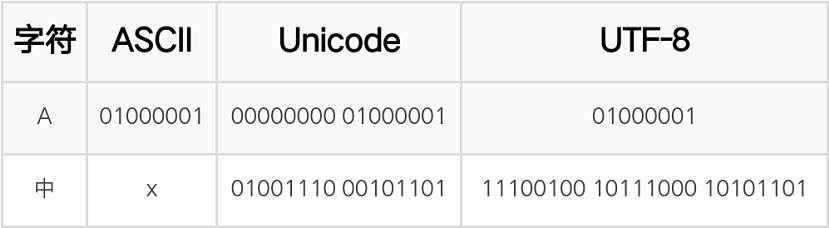
UTF-8、UTF-16、UTF-32区别
UTF 意思是 Unicode 转换格式(Unicode Transform Format), UTF-8、UTF-16、UTF-32 是为了在内存中存储字符而对 Unicode 字符编号进行编码。它们都是 Unicode 的实现方式,其中 UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。UTF-16(字符用 2 个字节或 4 个字节表示) 和 UTF-32(字符用 4 个字节表示),不过在互联网上基本不用。
UTF-16 使用 2 或 4 个字节进行存储。对于 Unicode 编号范围在 0~FFFF 之间的字符,统一用两个字节存储,无需字符转换,直接存储 Unicode 编号。对于 Unicode 字符编号在 10000-10FFFF 之间的字符,UTF16 用 4 个字节存储。
UTF-32 用固定长度的字节存储字符编码,不管 Unicode 字符编号需要几个字节,全部都用 4 个字节存储,直接存储 Unicode 编号。无需经过字符编号向字符编码的转换步骤,提高效率,用空间换时间。
GB2312、GBK、GB18030、GB13000之间的区别
GB2312
GB2312 或 GB2312-80 是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持 GB2312。
,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
- GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
- 对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
GB2312对任意一个图形字符都采用两个字节表示,并对所收汉字进行了“分区”处理,每区含有94个汉字/符号,分别对应第一字节和第二字节。这种表示方式也称为区位码。
- 01-09区为特殊符号。
- 16-55区为一级汉字,按拼音排序。
- 56-87区为二级汉字,按部首/笔画排序。
10-15区及88-94区则未有编码。
GBK
GBK即,为汉语拼音 Kuo Zhan(扩展)中“扩”字的声母。英文全称Chinese Internal Code Specification。
- GB2312中的全部汉字、非汉字符号。
- BIG5中的全部汉字。
- 与ISO 10646相应的国家标准GB13000中的其它CJK汉字,以上合计20902个汉字。
- 其它汉字、部首、符号,共计984个。
GBK向下与GB2312 完全兼容,向上支持ISO 10646国际标准,在前者向后者过渡过程中起到的承上启下的作用。
GBK 采用双字节表示,总体编码范围为8140-FEFE之间,首字节在81-FE之间,尾字节在40-FE之间,剔除XX7F一条线。GBK编码区分三部分:
汉字区
- GBK/2:OXBOA1-F7FE,收录GB2312汉字6763个,按原序排列。
- GBK/3:OX8140-AOFE,收录CJK汉字6080个。
- GBK/4:OXAA40-FEAO,收录CJK汉字和增补的汉字8160个。
图形符号区
- GBK/1:OXA1A1-A9FE,除GB2312的符号外,还增补了其它符号。
- GBK/5:OXA840-A9AO,扩除非汉字区。
用户自定义区
- GBK区域中的空白区,用户可以自己定义字符。
GBK 最初是由微软对 GB2312 的扩展,也就是CP936字码表 (Code Page 936)的扩展(原来的CP936和GB 2312-80一模一样),最初出现于Windows 95简体中文版中,由于Windows产品的流行和在大陆广泛被使用,中华人民共和国国家有关部门将其作为技术规范。注意 GBK 并非国家正式标准,只是国家技术监督局标准化司、电子工业部科技与质量监督司发布的“技术规范指导性文件”。虽然 GBK 收录了所有 Unicode 1.1 及 GB 13000.1-93 之中的汉字,但是编码方式与 Unicode 1.1 及 GB 13000.1-93 不同。仅仅是 GB2312 到 GB13000.1-93 之间的过渡方案。GBK 收录了 21886 个符号,它分为汉字区和图形符号区。汉字区包括 21003 个字符。
GBK 作为对 GB2312 的扩展,在现在的 Windows 系统中仍然使用代码页 CP936 表示,但是同样的 936 的代码页跟一开始的 936 的代码页只支持 GB2312 编码不同,现在的 936 代码页支持 GBK 的编码,GBK 同时也向下兼容 GB2312 编码。
GB18030
GB18030,全称是中华人民共和国现时最新的内码字集,是GB18030-2000《信息技术信息交换用汉字编码字符集基本集的扩充》的修订版。
GB18030 与 GB2312-1980 完全兼容,与 GBK 基本兼容,支持 GB13000 及 Unicode 的全部统一汉字,共收录汉字 70244 个。
- 与 UTF-8 相同,采用多字节编码,每个字可以由1个、2个或4个字节组成。
- 编码空间庞大,最多可定义161万个字符。
- 支持中国国内少数民族的文字,不需要动用造字区。
- 汉字收录范围包含繁体汉字以及日韩汉字
GB18030 编码是一二四字节变长编码。
- 单字节,其值从0到0x7F,与 ASCII 编码兼容。
- 双字节,第一个字节的值从0x81到0xFE,第二个字节的值从0x40到0xFE(不包括0x7F),与 GBK标准基本兼容。
- 四字节,第一个字节的值从0x81到0xFE,第二个字节的值从0x30到0x39,第三个字节从0x81到0xFE,第四个字节从0x30到0x39。
2000 年的 GB18030 取代了 GBK1.0 的正式国家标准。该标准收录了 27484 个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的 PC 平台必须支持 GB18030,对嵌入式产品暂不作要求。所以手机、MP3 一般只支持 GB2312。
GB18030 在 Windows 中的代码页是 CP54936。
GB13000
GB13000 等同于国际标准的《通用多八位编码字符集 (UCS)》 ISO10646.1,就是等同于 Unicode 的标准,代码页等等的都使用 UTF 的一套标准。
从 ASCII、GB2312、GBK 到 GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为 0。按照程序员的称呼,GB2312、GBK 到 GB18030 都属于双字节字符集 (DBCS)。
URL编解码
一般来说,网页URL只能使用英文、数字、还有一些特定的字符。根据网络标准RFC 1738做了硬性规定:
只有字母和数字[0-9a-zA-Z]、一些特殊符号”$-_.+!*’(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。
如果 URL中包括中文等字符,就必须经过编码后使用,否则传给服务器的 request URL 就会包含乱码,服务器无法正确识别。因为RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定,所以导致“URL编码”领域非常混乱。想要了解浏览器多种情况下的编码处理,可以参考阮一峰大神的关于URL编码。
- 网址路径的编码,用的是utf-8编码。
- 查询字符串的编码,用的是操作系统的默认编码。
- GET和POST方法的编码,用的是网页的编码。
- 在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是采用utf-8编码。
不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果,为了保证客户端只用一种编码方法向服务器发出请求,可以使用 Javascript 先对 URL 编码,然后再向服务器提交,不要给浏览器插手的机会。
编码方法有三种:escape(url)、encodeURL(url)、encodeURLComponent(url)
解码方法也有三种: unescape(url)、decodeURL(url)、decodeURLComponent(url)
| 方法 | 规则 | 特点 |
|---|---|---|
| escape、unescape | 除了ASCII字母、数字、标点符号”@ * _ + - . /“以外,对其他所有字符进行编码 | 它的作用是返回一个字符的 Unicode 编码值。现在已经不提倡使用这种方法了,它不能直接运用与 URL 编码。 |
| encodeURI(编码)decodeURI(解码) | 除了常见的符号以外,对其他一些在网址中有特殊含义的符号”; / ? : @ & = + $ , #”,也不进行编码 | encodeURI() 是 Javascript 中真正用来对 URL 编码的函数,它着眼于对整个URL 进行编码 |
| encodeURIComponent(编码)decodeURIComponent解码) | 在encodeURI()中不被编码的符号”; / ? : @ & = + $ , #”,在encodeURIComponent()中统统会被编码 | 与 encodeURI() 的区别是,它用于对 URL 的组成部分进行个别编码,而不用于对整个URL进行编码。 |
1 | > var url = "https://www.zhihu.com/question/342936488/answer/804030108"; |
Big Endian 和 Little Endian
- Little-endian:将低序字节存储在起始地址(低位编址)
- Big-endian:将高序字节存储在起始地址(高位编址)
例如,如果我们将 0x1234abcd 写入到以 0x0000 开始的内存中,则结果为:
| address | big-endian | little-endian |
|---|---|---|
| 0x0000 | 0x12 | 0xcd |
| 0x0001 | 0x34 | 0xab |
| 0x0002 | 0xab | 0x34 |
| 0x0003 | 0xcd | 0x12 |
对于字节序列的存储格式,目前有两大阵营,那就是 Motorola 的 PowerPC 系列 CPU 和 Intel 的 x86 系列 CPU。PowerPC 系列采用 big endian 方式存储数据,而 x86 系列则采用 little endian 方式存储数据。
所有网络协议也都是采用 big endian 的方式来传输数据的。所以有时我们也会把 big endian 方式称之为网络字节序。当两台采用不同字节序的主机通信时,在发送数据之前都必须经过字节序的转换成为网络字节序后再进行传输。
目前应该 little endian 是主流,因为在数据类型转换的时候(尤其是指针转换)不用考虑地址问题。
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格”(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用 big endian 方式;如果头两个字节是FF FE,就表示该文件采用 little endian 方式。
如何解决乱码问题
乱码本质上都是由于字符串原本的编码格式与读取时解析用的编码格式不一致导致的。
网页乱码问题
- 服务器返回的响应头 Content-Type 指明字符编码。
- 网页内使用 meta http-equiv 标签指定字符编码。
- 网页文件本身存储时使用的字符编码和网页声明的字符编码一致。
Java代码乱码问题
使用 getBytes() 方法指定编码。
使用字节流时指定编码。
使用 new String() 时指定编码。
使用 HttpClient post请求时指定编码。
1
2
3
4
5
6
7//请求实体
HttpEntity reqEntity = new ByteArrayEntity(reqStr.getBytes("UTF-8"));
httpPost.setEntity(reqEntity);
//请求实体
StringEntity reqEntity = new StringEntity(reqStr, Charset.forName("UTF-8"));
httpPost.setEntity(reqEntity);